
背景
移动端设备通常使用 Tiled Rendering,与桌面 / Console 端 GPU 的立即渲染模式不同,Tiled Rendering 会将 Frame buffer 划分为多个矩形片,每个矩形片称为一个 Tile,以此来减少带宽的消耗。
| Immediate Rendering | Tiled Rendering |
|---|---|
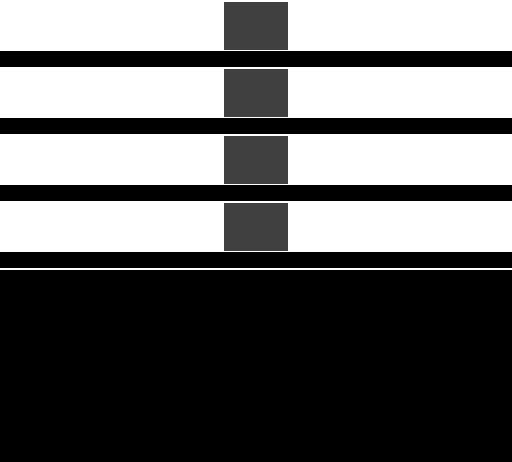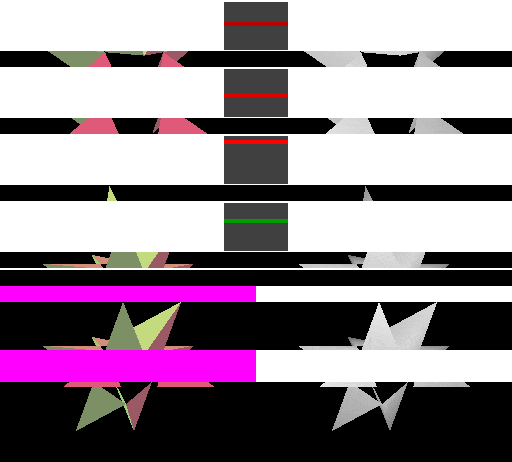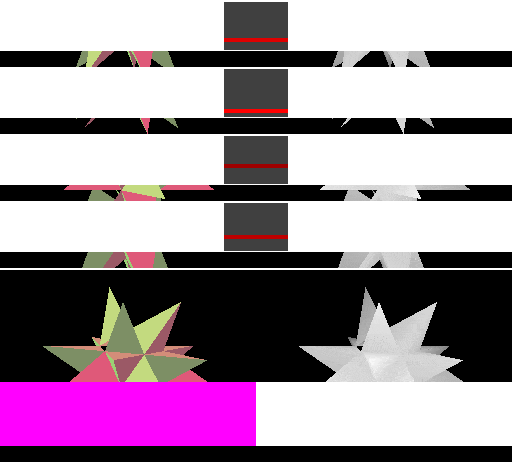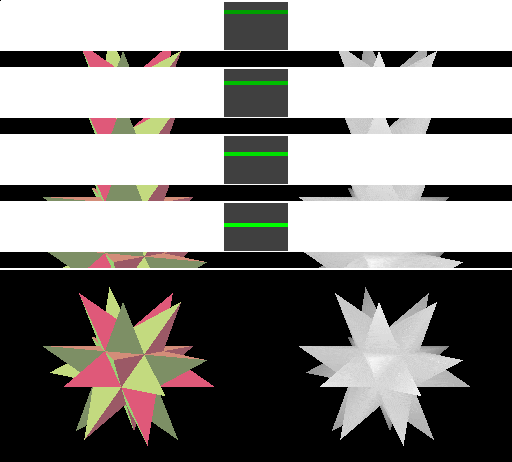 | 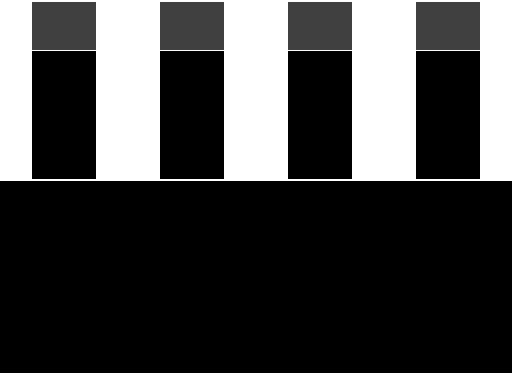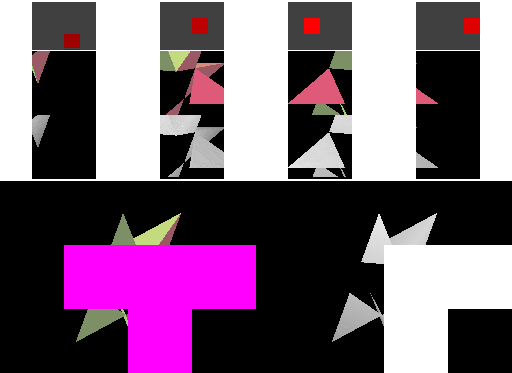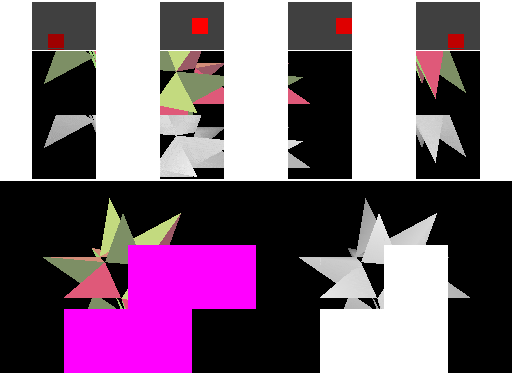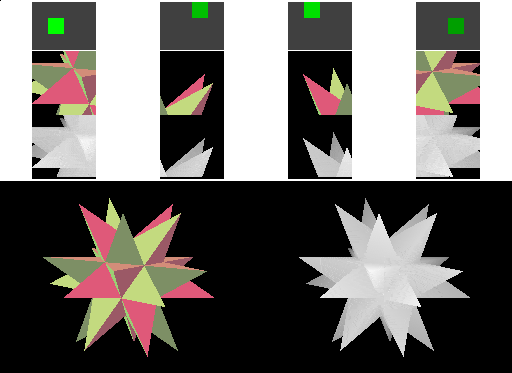 |
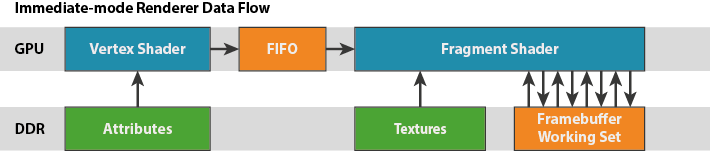 |  |
表格左边是使用 linear cacheline 的立即模式的绘制过程。渲染时,图像上方显示内存中四条连续的 cacheline。每个 cacheline 上方都有一个长条矩形,用于指示与 cacheline 对应的像素在 frame buffer 中的位置:红色表示 ache line 已写入但 cache miss,绿色表示 cache 命中,较亮的颜色表示最近访问过的 cacheline。与 miss 的 cacheline 对应的 frame buffer 像素以紫色(Frame buffer)和白色(Depth buffer)显示。
可见,立即模式的渲染可能会以不可预测的方式访问内存,因为具体的顺序取决于三角形是如何提交给 GPU 的。
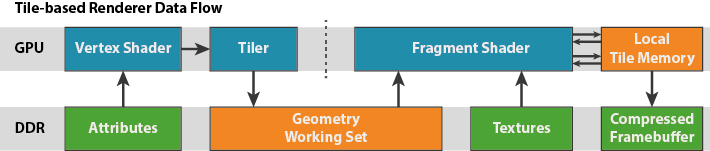
表格右边是使用 square cache tile 的 Tiled rendering 的绘制过程,上面的四个 cacheline 分别覆盖 frame buffer 和 depth buffer 中的一块矩形区域,然后紧接着是缓存的 frame buffer 区域和缓存的 depth buffer 区域。这里的 cacheline 所保存的像素数与使用 linear cache 的立即模式中相同。
在空间上接近的三角形,在提交的时间上一般也会比较接近,因此这种方式更好对缓存区域分组,从而提高缓存命中率。而且每个 tile 中会绘制更多的内容,相比立即模式,内存传输的频率有所降低,从而达到了减少带宽消耗的目的。可见,相较于立即模式,tiled rendering 拥有更好的局部性。
Tiled Memory
简单来说,Tiled Memory 是 GPU 芯片上的内存,与通用显存(系统内存)相比,具有带宽较高、延迟较低、功耗较小的特点。
Image layout transitions with VK_IMAGE_LAYOUT_UNDEFINED allow the implementation to discard the image subresource range, which can provide performance or power benefits. Tile-based architectures may be able to avoid flushing tile data to memory, and immediate style renderers may be able to achieve fast metadata clears to reinitialize frame buffer compression state, or similar.
移动 GPU 一般都有 Tile Memory。 , (还有一种与 Tile Memory 特性相反的系统内存。在移动设备中,CPU 和 GPU 通常共享此(物理)系统内存。)
Metal 或 Vulkan 可以显式声明一个 RenderPass 来决定是否将 Tile 内存移动到系统内存(如果下一个渲染过程中不需要 Tile 内存中某个渲染过程的输出,那么显式地声明您可以想要丢弃 tile 内存中的数据(Memory Less,不要将 tile 内存中的数据移动到显存)或在下一个渲染通道中按原样使用 tile 内存中的数据而不将其移动到显存(。您还可以节省内存带宽。)
然而,在 OpenGL ES 的情况下,没有 RenderPass 的概念,所以如果你想丢弃 Tile 内存中的数据而不将其移动到显存,可以使用 glClear 函数来通知 GPU 驱动程序这一点。但由于 OpenGL ES Spec 中没有有关 Tile 内存的信息,因此在调用 glClear 函数时是否执行此操作似乎因 GPU 驱动程序而异。
另外,在 MSAA 的情况下,存储像素值需要的内存是样本数量的 N 倍,但是 tile 内存的大小大于 MSAA 所需的内存大小,因此如果对 MSAA 采样数据可以存储在 tile 存储器中, tile 存储器存储 MSAA 的采样数据之后,可以在 tile 存储器中执行 MSAA 解析。
因此,使用 MSAA 时和不使用 MSAA 时,内存带宽使用量是相同的(通过在 tile 内存上执行 MSAA Resolve,从 tile 内存传输到显存的数据大小与使用 MSAA 时相同。因为 Tile 内存非常接近 GPU 核心,因此数据传输和访问速度比显存快得多。
Mali GPU 支持称为“像素本地存储”的功能,这意味着在着色器阶段声明数据存储在 Tile Memory 中。声明为像素本地存储的类型的数据在渲染过程中仅存在于 tile 内存中,并且被丢弃而不是复制到显存(系统内存),从而防止不必要的内存带宽浪费。移动 GPU 通过基于 tile 的渲染对场景中的所有图元进行顶点着色,然后收集每个 tile (将渲染目标划分为一定尺寸(基于 Mali GPU 的 16x16)的 tile )上要绘制的图元。在为要绘制的每个 tile 收集场景中(在几何工作集中)的所有原始三角形后,仅对屏幕上可见的三角形执行片段着色(丢弃被遮挡的片段)(隐藏表面移除)。 在移动 GPU 上,按如下方式完成:一次对场景中的所有三角形执行顶点着色,为每个 tile 收集数据,然后一次为每个 tile 执行片段着色。
这里,当对每个 tile 执行片段着色时,等于 tile 大小的渲染目标被存储在 tile 存储器中。 Pixel Local Storage 是程序员直接定义要存储在这个 Tile Memory 中的数据的地方,在移动 GPU 上执行延迟渲染时,如果在 G-buffer pass 和 Resolve pass 中使用 Pixel Local Storage,则存储 G-buffer。作为显存(系统内存),您可以通过将其存储在 Tile Memory 中并在 Resolve pass 中立即读取来节省内存带宽。此外,存储在 Tile Memory 中的 Pixel Local Storage 数据不会转移到显存(只是被丢弃),因此这里也可以减少内存使用量。